Blameless postmortem canvas
Discover how Byron Torres does Blameless postmortem canvas in Miro.
Follow this process means that engineers whose actions have contributed to an accident can give a detailed account of:
what actions they took at what time,
what effects they observed,
expectations they had,
assumptions they had made,
their understanding of timeline of events as they occurred.
and that they can give this detailed account without fear of punishment or retribution.
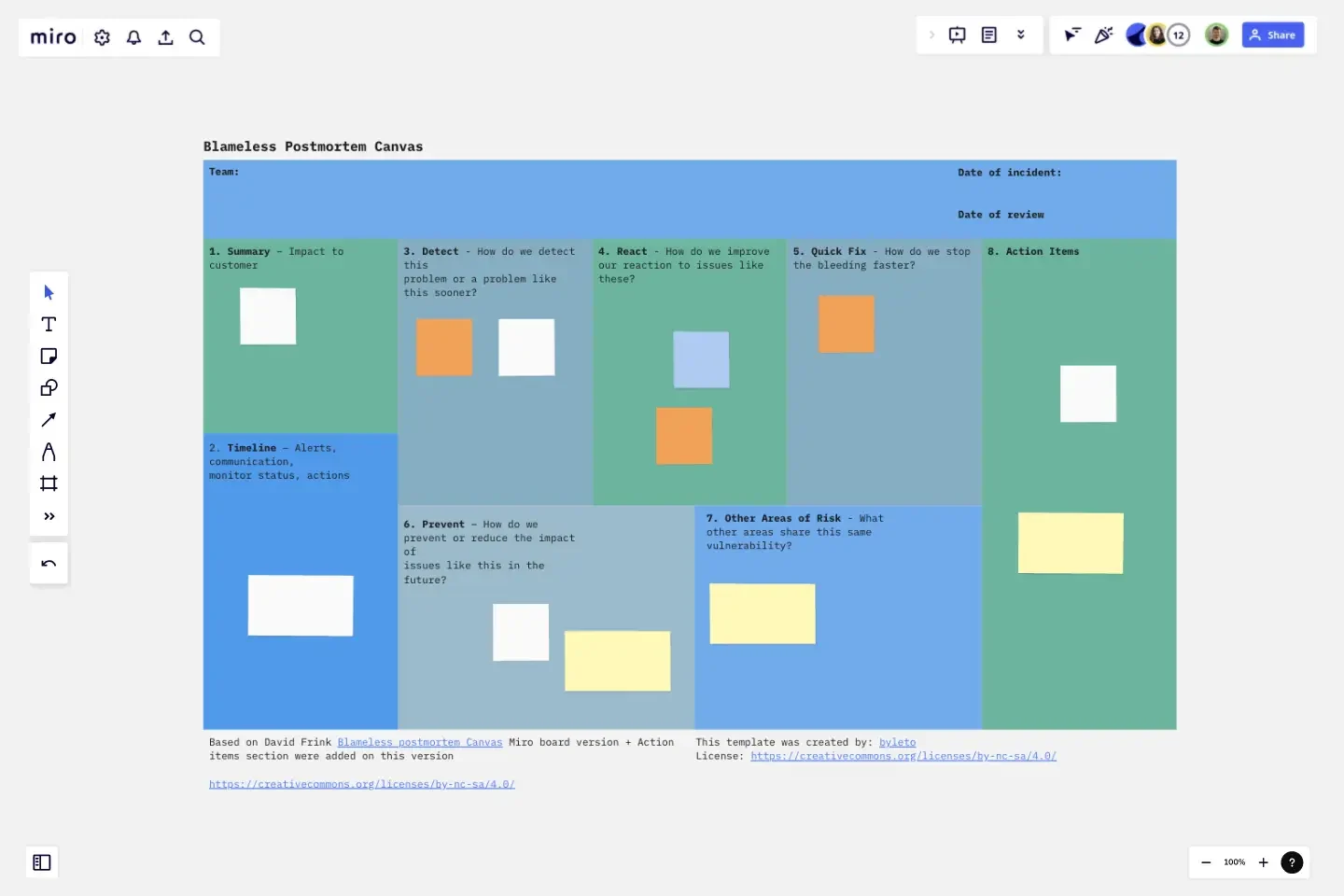
The Blameless postmortem includes the following sections
Step 1: Summary (pre-fill ahead of the meeting)
A high-level summary of the issue, focusing on what is known at this point and what the impact to the customer was. Keep this to a sentence or two.
Step 2: Rough Timeline (pre-fill ahead of the meeting)
A rough timeline of the issue. Depending on how fast-moving the issue was, this timeline could span a few minutes to a few hours to a few days. If your primary focus is on improving the team’s response times during emergencies, you’ll want this down to the second.
As you capture the timeline, be sure to include:
When the issue was reported and by whom/what process
What actions were taken
When communication was made into and out of the team
Remediation Ideas
When you meet to discuss the issue, invite everyone who worked the issue. This includes the production support team as well as the customer support team members that may have been involved.
Review the summary, review the time line and add any missing parts, then move into the remediation ideas.
These questions are formulated to help the team take ownership of the problem. There are some issues that feel like they are outside of the team’s control (data center loses power, etc). But even in events like those, the team can still improve their reaction to the disaster.
Step 3: Detect – How do we detect this problem or a problem like this sooner?
Assume this problem or a problem very much like it will happen again. How can the support team detect this problem faster and find it before a customer does?
Step 4: React – How do we improve our reaction to issues like these?
Assume the issue is reported. How quick was the reaction? Were minutes lost while people were sending emails around trying to get someone to look at the problem?
The next time this issue happens, how can the team react more quickly or in a more organized fashion?
Step 5: Quick Fix – How do we stop the bleeding faster?
When this happens again, is there a ready workaround that we can provide the customer to reduce the impact of the problem?
If this is something that gets worse over time (like a DDOS attack) do we have a quick way to close the flood gates while we figure out the root cause?
Step 6: Prevent – How do we prevent or reduce the impact of issues like in the future?
This is often the only question teams ask in a postmortem. It is an important question and you should spend a lot of time here. However, if you limit yourself to asking only how to prevent an issue, it lets you not take any responsibility for the things within your control (like how you detect, react or quick fix an issue).
As you brainstorm ideas, don’t limit yourself to technical fixes. Better monitoring, better communication paths, better training, making sure the people in customer support know the people in production support by name, etc.
Step 7: Other Areas of Risk – What other areas share this same vulnerability?
Every issue is a hint at where your system is weak. Odds are, for each issue you find, there are dozens lurking in the shadows, yet to be found.
Kind of like if you see a mouse in your kitchen. You don’t have a “mouse” problem, you’ve got a “mice” problem.
There are likely other parts of the system that share the same design assumptions or in some cases the same code (not that anyone would ever copy/paste code).
Spend a few minutes brainstorming for other places that are vulnerable in a similar way.
When teams are stressed and overworked, they will skip this step. I find that this is the most important question to ask to get the team into a proactive mindset and to reduce the occurrence of issues in the future.
Step 8: Next Steps (Actions)
After you’ve identified all the possible things you can do to improve how issues are detected, reacted to, quick fixed and prevented…and you’ve found the other areas of your application that need attention…move on to deciding which actions to take.
The way you prioritize these is up to you. But I do have a few pieces of advice.
Get a name and a date on each one you plan to action before you leave the meeting
If someone in the meeting is passionate about taking one of the actions, encourage them to, even if you think it might not be the most important thing to fix
Names and Dates
Generally, I’ve found that teams enjoy this exercise (provided you can create a blameless environment for the meeting). They like dissecting the problem and brainstorming solutions. However, everyone feels busy and overworked. Unless this meeting wraps with owners and dates next to the things that need to be done, the greatest likelihood is that none of the improvements will happen.
What will happen is that 3 weeks from now when the same problem occurs on production (but this time in a bigger way) someone will say, “oh yeah, we talked about fixing that.” Not a great place to be.
To combat that, simply ensure that there is a name and date next to each action that the group wants to take.
This template was created by Byron Torres.
Get started with this template right now.
Startup Canvas Template
Works best for:
Leadership, Documentation, Strategic Planning
A Startup Canvas helps founders express and map out a new business idea in a less formal format than a traditional business plan. Startup Canvases are a useful visual map for founders who want to judge their new business idea’s strengths and weaknesses. This Canvas can be used as a framework to quickly articulate your business idea’s value proposition, problem, solution, market, team, marketing channels, customer segment, external risks, and Key Performance Indicators. By articulating factors like success, viability, vision, and value to the customer, founders can make a concise case for why a new product or service should exist and get funded.

Canvas Playground Template
Works best for:
Templates
The canvas playground template is the ultimate way to explore all the features that make up Miro's Intelligent Canvas. This dynamic and interactive space is designed to help you get work done faster while engaging your team. From AI creation and Sidekicks to intelligent widgets, this template allows you to try it all and discover how these capabilities can streamline your workflow and enhance collaboration.
Sailboat Retro
Works best for:
Retrospectives, Agile Methodology, Meetings
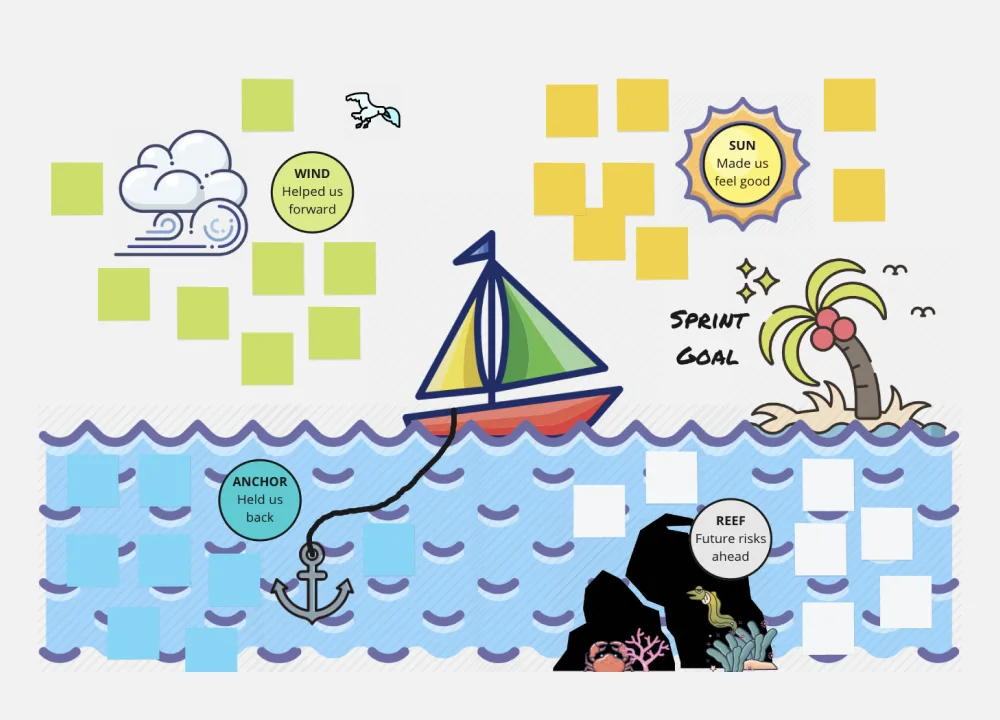
The Sailboat Retrospective template offers a metaphorical journey through past iterations and future goals, likening the retrospective process to sailing a boat. It provides elements for identifying driving forces (winds), restraining forces (anchors), and destination (goal). This template enables teams to reflect on what propels them forward, what holds them back, and where they want to go next. By promoting visualization and metaphorical thinking, the Sailboat Retrospective empowers teams to navigate challenges, set sail towards their objectives, and steer towards success effectively.
DevOps Roadmap Template
Works best for:
Documentation, Product Management, Software Development
DevOps teams are constantly creating code, iterating, and pushing it live. Against this backdrop of continuous development, it can be hard to stay abreast of your projects. Use this DevOps Roadmap template to get a granular view of the product development process and how it fits into your organization's product strategy. The DevOps Roadmap lays out the development and operations initiatives you have planned in the short term, including milestones and dependencies. This easy-to-use format is easily digestible for audiences such as product, development, and IT ops.
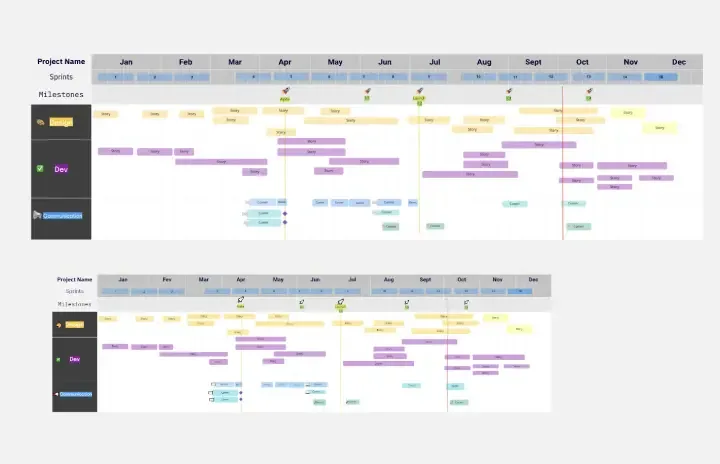
Project - Timeline & Key Infos
Works best for:
Agile, Project Management
The Project - Timeline & Key Infos template provides a visual framework for planning and tracking project timelines, milestones, and key information. It enables teams to align on project objectives, allocate resources, and monitor progress effectively. With customizable timelines and informative dashboards, this template empowers project managers and stakeholders to stay organized and informed throughout the project lifecycle, ensuring successful delivery within scope, time, and budget constraints.

User Story Map Template
Works best for:
Marketing, Desk Research, Mapping
Popularized by Jeff Patton in 2005, the user story mapping technique is an agile way to manage product backlogs. Whether you’re working alone or with a product team, you can leverage user story mapping to plan product releases. User story maps help teams stay focused on the business value and release features that customers care about. The framework helps to get a shared understanding for the cross-functional team of what needs to be done to satisfy customers' needs.